

Q. I've recently had a 9kW system installed and the inverter reports power production of around 40kWh on a mostly sunny day. In the 55 days since the system was installed the inverter claims to have produced 2.318MWh of power.
Our fist bill from our energy supplier tells us the recently installed net meter is recording a solar input of only 7.9kWh per day.
This seems to be a large difference to me. Is there any chance the numbers from the invertor and metre can be correct? I've asked both the installer and power company for details.
A. The short explanation is this: your electricity meter does not know how much solar you have generated. It only knows how much you have exported. The solar number on your bill is the net amount of solar sent into the grid, after your house has self-consumed any solar power it needs. So it looks like you self consume about 33kWh of solar per day.
If that answer leaves you confused, here is the longer answer:
The fundamental principle of grid connected solar power is that your solar will first get used by your house (as 'free electricity'), then any surplus will be exported to the grid earning a feed-in-tariff..
When you install solar, the amount of solar electricity you export will need to be measured so you can get paid for it. You'll either get a new meter or get your existing meter re-configured. The new meter is called a 'net meter' (note this is different from a 'smart meter' - a smart meter uses wireless communications to send your usage to the retailer, a net meter simply measures solar exports - it may or may not also be a 'smart meter').
Your new meter has two counters:
Counter #1: Imports. This shows how much energy you import from the grid. You import from the grid when your house is using more than you generate with your panels at any moment in time. You pay the retail electricity rate for every kWh of electricity you import. This price can vary from around 20c to 40c per kWh depending on your tariff.
Counter #2: Exports. This shows how much energy you export to the grid. You export when your panels are generating more solar than your house can use at any moment in time. You get paid a feed-in tariff for every kWh of electricity you export. As mentioned, this is generally from 6-16c per kWh depending on the retailer.
Note the meter does not actually know how much total electricity you are using in your home. I know, I know, that sounds totally counter intuitive, but bear with me.
Here's a block diagram of your meter, your panels and the energy flows:
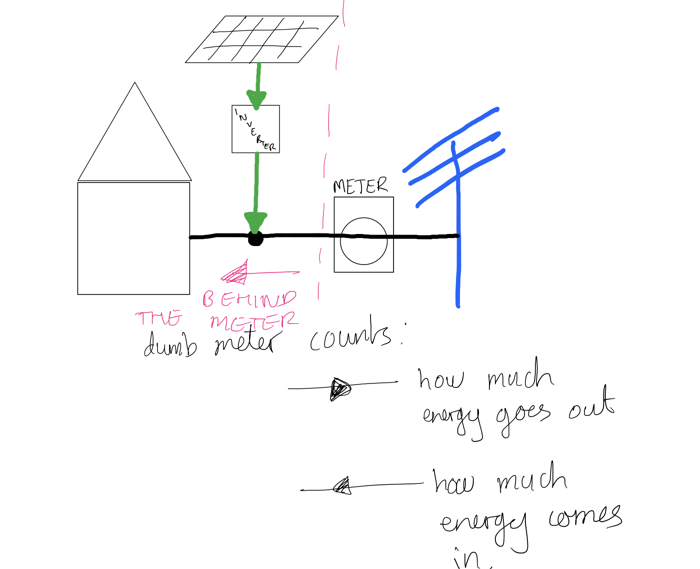
You can see that I call everything to the left of the meter 'behind the meter'. This is because the meter cannot see what is happening on the left of the red line. It is not a smart meter, it is quite dumb. It can only measure how much energy goes into your house and out of your house.
Consider the situation where there is surplus solar. That is you are generating more solar than your house can use. Some solar is being consumed by the house and the rest is exported to the grid:
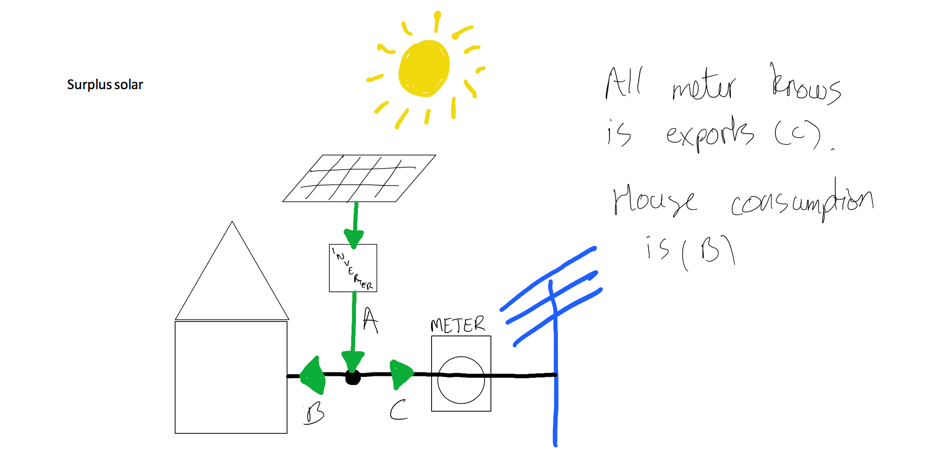
Your meter does not know how much solar is being generated (A) or how much solar your house is using (B). it only knows how much you are exporting ( C ). This is what you get paid for, and this is the number that appears on your electricity bill.
This number on your bill will always be less than the number on your inverter, because your bill shows exports (generation minus self-consumption), whereas your inverter shows gross generation.
If you want to see the full picture (A, B and C in the diagram above), then I recommend investing in 3rd party monitoring:
Comments
0 comments
Please sign in to leave a comment.